A new category of database technology for a richer data story
At Event Store, we recently analyzed our top fintech clients overwhelmed by the minefield of database options. We know many more software architects at financial companies are out there creating new applications and considering new data models—all expecting more from what’s currently available.
At the most fundamental level, storing data—without losing any of it—is absolutely essential. But financial companies also need to organize and access their data efficiently, so they can quickly understand customers, predict trends in customer behavior, and tailor interactions.
That’s why many fintechs and financial companies have opted for a new database technology, which maintains the fast distribution of information, keeps an audit trail of who did what, and helps meet regulations.
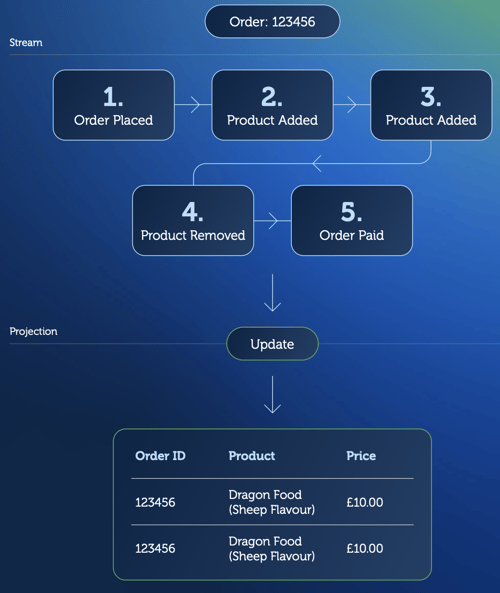
Instead of saving just the current version of the entity state into a database, this new data model stores each state transition and names it as a separate record called an event.
This means the order and business context of state changes are kept, transforming modern enterprises' data into real-time actionable streams. We implement this “source of truth” database at Event Store, and it is a confluence of two macro trends: the evolution of operational database technology and event-driven architecture (EDA)
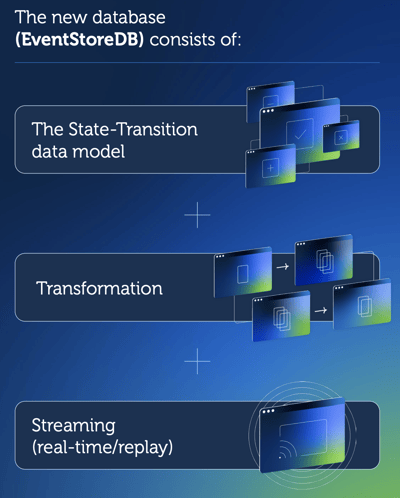
It keeps data at its most fundamental level, streams it in real-time, and transforms data into any other shape needed by downstream data technologies. When business requirements change or new analytics technology emerge, it allows developers to replay from the beginning of time. EventStoreDB forces developers to analyze and address the impact of data changes on historical data, not just to the current state data like traditional databases. This is fundamental for enterprises to take advantage of the explosion of innovation in analytics and AI.
Storing the why to turn data into limitless business insights
So, you may be wondering: “But if I store all the events, doesn’t that lead to clutter? Why would I want to do that? And why not stream events instead?” Well, when developers come across a data problem, they want to work out how they got to that state. But it’s hard to track backward with old data models where events have not been stored. They need an operational database with real-time events storage.
Financial companies are now after an easier way to see the why of an immutable sequence of changes—and a way for no data to be lost, overwritten, or unavailable. This new data model is a simple yet powerful concept that records not just what’s changed, but the order those changes occurred. This creates a permanent, unchangeable log of all the transitions the data has gone through.
Take this simplified example of a shopping basket:
- The state of this shopping basket is empty.
- I add a milk carton to my basket, so the state changes.
- I add juice too, and the state changes again.
- Then, I decide I don’t want to buy the milk and take it out. I only buy the juice.
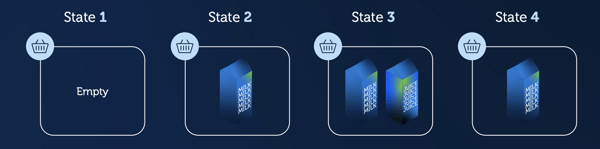
What’s more valuable? Knowing only what the customer bought (the end state), or every single event that led up to it?
Most developers are trained to look deeply at the system they are building and care less about what’s happening on the outside. But we are storing the why, so the database becomes business-focused. Developers need to be interested in their company’s trajectory.
By storing data as a state transition event with a sequence number, worlds of possibilities appear: A developer with any technology stack can find where the events are in the stream of changes. By knowing that, events can be replayed from any point in the sequence, which could help with calculating pricing models and updating inventory lists in a financial company.
The idea is far from new! We can find examples from many environments—like a bank account ledger. Our current account balance could be represented as a number and a currency (10 EUR) or as the result of the sum of all the transactions (0 EUR + 20 EUR + (-15 EUR) + 5 EUR).
Also, with this new category of database, streams can be transformed into other streams that serve as input for app-specific integration, enabling businesses to maximize the value of event data and use it to boost business processes.
You can also inject new analytic methods into old data to find new insights. Imagine using your analytics engine on years of old data and discovering your business could have been more effective and profitable with some minor changes.
If you are unsure what the advantages of EventStoreDB are over traditional databases, or you’ve had trouble convincing your CTO to update legacy systems, we’re here to help.